-
[산대특] Oracle10g JOIN(INNER, OUTER, SELF), 집합(Set) 연산자, SubQuery, Group by(Rollup, Cube), Transaction(Rollback, Lock), View Table, Index[산대특]클라우드기반 빅데이터 활용 정보 시스템보안과정/DBMS 2024. 10. 7. 17:32
1007
JOIN
단일 테이블에서 정보를 쿼리, 두 세 개의 테이블에서 정보를 쿼리하는 경우도 많다.
Join으로 여러 테이블들을 묶어서 쿼리하는데 FROM ~ 절에 원하는 항목이 들어 있는 테이블들을 지정해주면 된다.
원하는 정보가 두 개나 그 이상의 테이블에 존재하기 때문에 이런 경우
두 테이블을 조인해서 값을 얻어오는 처리를 해야 한다.
조인이 필요할 때에는 먼저
1) 요구하는 정보(컬럼_명, 항목)는 무엇인가,
2) 요구하는 이 정보는 어느 테이블에 들어 있나,
3) 두(세)개 테이블을 조인한다면 각 테이블에서 서로 공통적으로 들어있는 열_명
(관계형 데이터베이스이기 때문에 각 테이블은 특정 항목에서 PK와 FK의 관계가 적어도 하나씩은 있다)
이 무엇인지 살피는데, 이 항목을 근거로 해서 조인이 이뤄지는 것이다.
이렇게 공통적인 항목(열_명)이 있는 테이블 사이에서 Join이 일어난다.
4) 조인에는 Inner, Outer, Self, Full 등이 있으므로 적절히 지정해서 작업해주면 된다.
Join에는 Oracle join과 ANSI join 두 가지가 있다.
JOIN을 명시적으로 지정하는 기법이 ANSI Join 기법이다.
두 테이블 조인
=>employees 테이블에는 employee_id가 156과 100인 두 명의 last_name이 'King'인 사용자가 있는데,
이들의 department_name을 보이시오.
select e.employee_id, e.last_name, d.department_name
from employees e, departments d
where last_name='King'
and e.department_id=d.department_id; <=오라클 조인
OR
select employee_id, last_name, department_name
from employees e (INNER) JOIN departments d
ON e.department_id = d.department_id
where last_name='King'; <=ANSI 조인
세 테이블 조인
=>두 King 사원의 월급(salary), 이름(last_name), 사원번호(employee_id), 직무(job_title),
그리고 부서이름(department_name)을 질의해보자.
select employee_id, last_name, salary, job_title, department_name
from employees e
JOIN jobs j ON e.job_id = j.job_id
JOIN departments d ON e.department_id = d.department_id
AND last_name='King'; <=오라클 조인
OR
select employee_id, last_name, salary, job_title, department_name
from employees e, jobs j, departments d
where e.job_id=j.job_id
and e.department_id=d.department_id
AND last_name='King'; <=ANSI 조인
b. Outer join
Outer Join은 조인하는 두 테이블에서 항목/데이터의 수가 다를 때 이를 커버해주면서 조인해주는 기법이다.
여기에는 right outer join과 left outer join 두 가지가 있는데 right/left의 선택은 항목 수가 더 많은 테이블을 오른쪽에 두면 right, 왼쪽이면 left를 써준다. <=ANSI JOIN
OR Oracle Join으로 한다면 부족한 테이블 (+)를 써준다.
두 쿼리의 결과가 다르다. =>올바른 쿼리가 아니다!!!
=>Outer Join이 필요하다...
c. SELF JOIN
Self 조인은 하나의 테이블을 Alias로 구분해서 마치 두 테이블인 것처럼 만들어 놓고 JOIN 해주는 기법이다. JOIN 시 ON ~ 부분에서는 동일한 테이블에서의 열_명이라 FK를 사용하지 않아서 쿼리에 맞게 열_명이 서로 다를 수 있으므로 주의한다.
departments 테이블에서 department_name이 Executive인
각 사원의 last_name과 해당 사원의 부서장의 last_name을 보이시오.
select employee_id, last_name, d.manager_id
from employees e JOIN departments d
ON d.department_id=e.department_id
where department_name='Executive'; 해
주면 두 명의 사수가 100인데 이를 employees 테이블에서 last_name으로 찾아 주어야 한다. <=Self join 필요
select A.employee_id, A.last_name as emp_name, B.last_name as mgr_name
from employees A JOIN employees B
ON A.manager_id=B.employee_id
JOIN departments D
ON A.department_id=D.department_id
where D.department_name='Executive';
OR 이를 서브쿼리를 이용할 수도 있다.
select last_name, department_name, (SELECT last_name FROM employees where employee_id=e.manager_id) "MRG_NAME"
from employees e JOIN departments d
on e.department_id=d.department_id
where department_name='Executive';
집합(Set) 연산자
두 테이블에서 SELECT 문으로 각각 데이터를 조회한 뒤 새로운 데이터로 가공하고 싶을 때 집합 연산자를 사용.
Set 연산자를 사용하기 위해서는 두 테이블에서 SELECT 문의 컬럼_명, 컬럼_위치, 컬럼_수가 동일.
SELECT 문을 활용한 Set 연산자에는
union(합집합), minus(차집합), 그리고 intersect(교집합)이 있다.
UNION(합집합)과 UNION ALL
데이터 수는 달라도 열의 수가 두 테이블에서 동일
UNION은 중복된 행을 제거하고, 두 쿼리의 결과를 결합
UNION ALL은 중복된 행도 포함하여 결과를 결합
SubQuery
첫 번째 SELECT ~ 문을 Main Query 문, 두 번째 이하의 SELECT ~ 문을 Sub Query 문,
Main SELECT ~ 문 안에 Sub SELECT ~ 문이 들어가는 것.
서브쿼리의 결과 값을 Scala 값, SQL에서의 단일 값.
Sub Query의 수행 결과는 하나의 값(Scala 값)으로 반환.
▸ 하나의 행으로 출력되는 단일 행 서브쿼리,
▸ 여러 행으로 출력되는
IN(하나라도 일치하면 true),
ANY/SOME(결과가 1개 이상이면 true),
ALL(모든 결과가 일치하면 true),
EXISTS(서브 쿼리의 결과가 있으면 true)와 함께 사용되는 다중 행 서브쿼리,
▸ 서브 쿼리의 select 문에 비교할 여러 대상을 넣는 다중 열 서브쿼리가 있다.
▸ 이 외에도 Inline-view와 with-절, Scala Sub Query 등이 있다.
대부분 서브 쿼리 절에는 order by 절을 사용할 수 없다.
비교 대상과 같은 자료형과 같은 개수로 지정
서브 쿼리에 있는 select 절의 수행 결과로 나오는 행의 수는 메인 쿼리의 연산자 종류와 호환되어야 한다는 등의 특징
GROUP BY 확장
GROUP BY를 확장해서 추가적인 작업을 할 수 있는데 group by rollup과 group by cube 함수를 사용.
GROUP BY ROLLUP
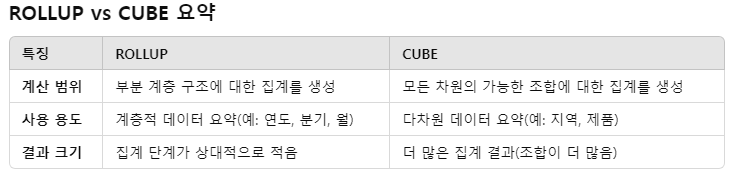
a. GROUP BY ROLLUP은 그룹화 할 조건이 있으면 우측으로부터 하나씩 제외해 나아가면서 그 결과를 반환하는 기능



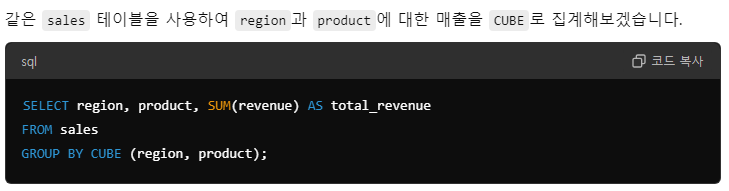
b. GROUP BY CUBE
GROUP BY CUBE는 3차원적인 분석을 가능하게 해주는 기능

계층적 질의
시작점을 지정한 뒤, --- 등으로 순서 레벨(계층)을 표시해줄 수 있다.
---를 세개씩 채워서 계층을 표시해준다.
Transaction & RollBack, Lock
트랜잭션이란 하나의 연관되어 완성되는 작업 단위이다.
완전히 DML 과정을 종료시키려면 commit(OR /) 해서 프로세스를 완료,
rollback을 해서 프로세스를 취소
=>간단히 말해서 트랜젝션은 일련의 작업의 완성, 롤백은 일련의 작업의 취소이다.
LOCK
LOCK는 TRANSACTION과 긴밀하게 연관
commit 해서 해당 작업을 완료하지 않는 한,
사용자 B가 똑같은 테이블 A의 동일한 항목에 대해서 쿼리나 변경 등의 작업을 시도
이전 사용자 A의 작업이 마무리되지 않았기 때문에 사용자 B의 작업도 수행되지 않는 TABLE LOCK가 발생
=> 사용자 A가 여전히 테이블 A의 해당 항목(열)에 대한 프로세스를 잡고 있기 때문에
사용자 B가 해당 프로세스를 사용할 수 없기 때문
뷰(View)
미리 필요한 항목들만 각 테이블을 JOIN 한 뒤 추출해서 뷰 테이블로 저장해두고
나중에 일반 테이블처럼 JOIN 없이 사용할 수 있다.
가상_테이블이라고도 한다.
뷰는 명령어와 스크립트로 생성할 수 있는데 JOIN 하는 과정을 스크립트를 만들어 두거나
STORED PROCEDURE를 사용해서 데이터베이스 서버에 저장해두고 수시로 꺼내서 수정해가면서 재사용
STORED PROCEDURE는 데이터베이스에 저장되어 관리
최초 compile 한 이후로는 그냥 수정해서 실행하기만 하면 된다.
View에서 몇 가지 주의 점은
a) 쿼리 시 맨 끝에 where read only를 붙이면 수정을 못하는 ‘읽기 전용’ 뷰가 된다.
b) view 테이블에서의 데이터 변경은
▪ 하나의 테이블에서 필요한 항목들만 추출해서 만드는 단순 뷰는
INSERT, UPDATE, DELETE가 자유로우며 (NOT NULL 컬럼 주의)
▪ 여러 테이블들을 조인해서 필요한 항목들만 추출해서 만드는 복합 뷰는
함수, UNION, GROUP BY 등을 사용하기 때문에 INSERT, UPDATE, DELETE가 불가능. 하지만 JOIN만 사용한 복합 뷰인 경우 제한적으로 가능하다.
c) 뷰 가상 테이블에서 데이터를 변경하면 뷰가 참조하고 있는 원본 테이블에서도 데이터가 변경된다!!! 원본 테이블과 이 가상 뷰 테이블이 링크되어 있는 것을 볼 수 있다.
d) 그리고 일단 view로 생성한 뷰_테이블_명을 변경할 수 없다.
복합 뷰를 생성할 때에는 Join을 하는데
a. 일단 해당 항목이 들어 있는 테이블들을 desc table_name 해서 항목을 보고,
b. 각 테이블의 상호 공통_항목(열_명)을 추려둔다.
select view_name, text from USER_VIEWS; 하면 생성한 뷰를 확인.
생성된 뷰 테이블에서 다른 뷰 테이블을 또 다시 생성가능.
원본에서 데이터를 변경, 뷰 테이블에서 데이터를 변경 => 원본과 뷰 테이블 두 곳에서 모두 변경
뷰 테이블 생성을 스크립트로 만든 뒤 필요하면 변경해서 여러번 사용할 수 있다.
인덱스(Index)
인덱스는 테이블에 있는 데이터에 보다 빠르게 접근하기 위해서(쿼리를 빠르게 수행) 설계된 기능
Oracle에서의 데이터베이스 저장 공간(네임스페이스)에 저장되며 Oracle이 자동으로 관리
=>데이터베이스 튜닝(tuning)은 바로 이 인덱스를 조정하는 작업이라고 할 수도 있다.
보통 전체 데이터에서 2%에 해당되는 정보를 추출해야 한다면 인덱스가 유리
=>특정 항목에 대한 인덱스를 생성한 뒤 해당 항목으로 쿼리하면 인덱스가 적용되어 쿼리가 빨라진다.
또 예를 들어서 Index가 없어도
PK를 index로 해서 rowid로 찾기 때문에 111을 훨씬 빠르게 찾는다.
'[산대특]클라우드기반 빅데이터 활용 정보 시스템보안과정 > DBMS' 카테고리의 다른 글
[산대특] MySQL, WorkBench, PHP (DB 끝!) (0) 2024.10.10 [산대특] Oracle10g[Role, Privilege Delegation, SYNONYM, DATA DICTIONARY, MERGE, Trigger, Cursor], MySQL (0) 2024.10.10 [산대특] Oracle10g 테이블 생성, 복제, 제거, PK/FK, 제약 조건 (4) 2024.10.02 [산대특] Oracle10g 표준 내장 함수, Group by, dual (2) 2024.10.01 [산대특] 데이터베이스, Oracle, SQL, SQLplus (3) 2024.09.30