[산대특] 리눅스의 명령어의 바다 탐색
0823
| |(pipe, vertical bar) | 명령어를 연결시켜주는 |
| tr | 문자열을 변경해주는 |
ShellScrpt 에서는 || 는 OR 의 의미, && 는 AND 의 의미
| grep 은 특별히 Filtering 해주는 기능
| more/less 는 긴 문장을 한 페이지 씩 갈무리 해서 볼 수 있음
grep, more, less 도 파일을 읽을 수 있다.
실습!
[root@centos7-10-1 centos]# dmesg
시스템에서 발생하는 메세지
너무 많으면
[root@centos7-10-1 centos]# dmesg | more/less
이렇게
more 를 쓰면 한페이지씩 볼 수 있고, less 는 vi 화면으로 볼 수 있다.
[root@centos7-10-1 centos]# cat -n /etc/passwd | grep "root"


[root@centos7-10-1 centos]# more /etc/passwd
[root@centos7-10-1 centos]# less /etc/passwd
이렇게 가능하다

[root@centos7-10-1 centos]# cat -n /etc/passwd | tr 'root' 'ROOT' | grep 'ROOT'
줄번호로 쫙 보이고 | 그 중에서 root 를 ROOT 로 바꾸고 | ROOT 있는 줄말 보여

단어? 문장?를 바꾸려면 substring 을 써야 한다. (좀이따!)

-i 는 대소문자 구분하지 않는다.

이렇게 해도 똑같이 나온다.
wc wordcount
파일의 문자수(c), 단어 수(w), 줄의 수(l) 등을 보인다.
실습

[root@centos7-10-1 centos]# wc input.txt
4 9 52 input.txt
순서대로 줄수, 단어수, 문자수



root 가 두번 나온다.
stat
파일에 대한 Access, Modify, Change 등을 보인다.
이걸로 중요한 파일 등에 대해서 수정, 접근 기록 을 잘 봐야한다.
실습
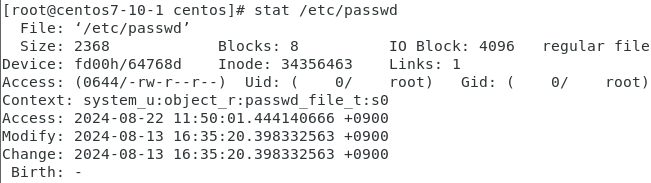
context 는 해당 파일에 대한 보안 설정을 뜻한다.
수정 변경 등 정보를 볼 수 있다.
[root@centos7-10-1 centos]# adduser paul
[root@centos7-10-1 centos]# passwd paul
Changing password for user paul.
New password: paul
BAD PASSWORD: The password is shorter than 8 characters
Retype new password: paul
passwd: all authentication tokens updated successfully.
사용자를 만들면

이 두 파일에 영향을 미친다. 기록된다.

파일을 열지 않아도 작업을 통해 stat 에 기록이 된다.
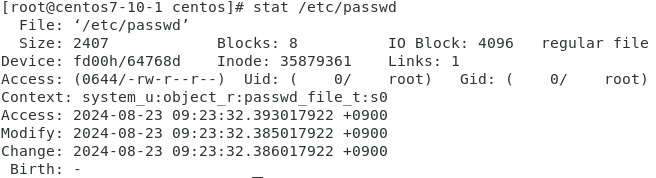
아까와 달리 날짜가 바뀌었다.
어느 파일이나 명령어의 위치를 알려주는 which, whereis, locate
실습

locate ssh
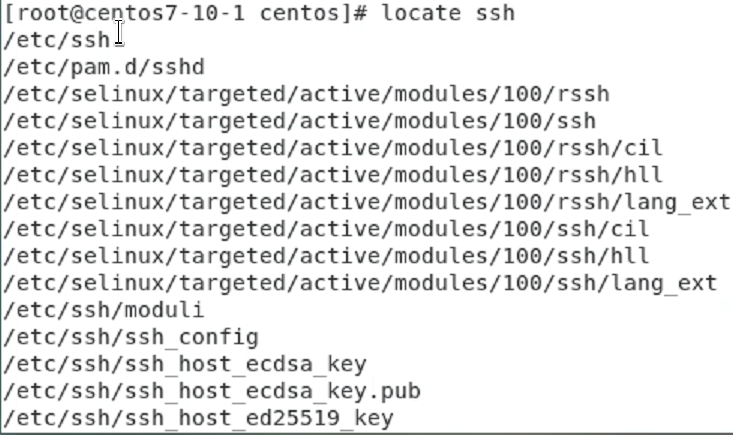


find 할 때 저게 나올 떄가 많은대 그럴때 저렇게 umount 시키면

잘 나온다.
echo 값을 읽거나 화면에 띄운다.
실습
[root@centos7-10-1 centos]# echo "IM Tired this morning" > cet.txt
[root@centos7-10-1 centos]# cat cet.txt
IM Tired this morning
[root@centos7-10-1 centos]# echo $HOSTNAME
centos7-10-1
[root@centos7-10-1 centos]# echo "1" > /proc/sys/net/ipv4/ip_forward
저기 /proc 파일은 가상파일 시스템이다.
이 파일은
MitM
Man in the middle 공격에서 많이 사용하는
A 와 B 사이에 가운데에 ip_forward = 1 을 집어넣으면 패킷을 보고 지나치게 해준다.
MitM => session hijacking
제대로 이해 못함
나중에 실습


웹에서 파일을 다운로드/복사 해오는 명령어
wget, git, curl, lftp, lftpget
lftp 는 다운로드가 실패했을 때 에러를 예외처리해서 다시 받아주고 2GB 이상의 대용량 파일도 다운받아주며 방화벽이 있어도 우회해서 받게 해준다.
실습

Download 링크를 카피
이런식으로 다운로드가 가능하고,
[root@centos7-10-1 centos]# wget -c ftp://ftp.gnu.org/pub/gnu/wget/wget-latest.tar.gz
요런 방법도 있다.
-c 는 continue 라는 뜻. 중간에 잘 안되도 멈추지 말고 이어하라
curl 도 있다.
[root@centos7-10-1 centos]# curl -O abc.git https://github.com/docker/docker.git > abc.git
이런식으로도 가능하다.
[root@centos7-10-1 centos]# git clone https://github.com/docker/docker.git
이렇게도 가능하다.

형상서버(Configuration Managemnet Server)
늘 업데이트 되는 웹상의 저장소를 로컬에 옮겨놓은 개념
FTP 서버는
파일을 업/다운로드 하게 해주고, 로그인 업시 사용 가능하다.
나만 알고 나만 연결 = active-mode, 주는대로 받는것이 passive-mode
lftp 실습
[root@centos7-10-1 docker]# yum -y install lftp
[root@centos7-10-1 docker]# nano /etc/lftp.conf
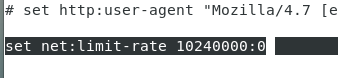
맨 아래에 추가
10240000 가 10메가
:0 은 업로드. 0은 무한
다운로드는 10메가씩 업로드는 무한
[root@centos7-10-1 docker]# lftp -c "set ftp:passive-mode on;set net:max-retries 3;set net:timeout 5;mget -c ftp://ftp.intel.com/readme.txt"

-c 컨티뉴
ftp 는 무료이다. 무료이며 사용자를 지정하지 않는 것을 anonymous
로그인 시도 최대 3번
passive mode 이다 너가 포트 주면 받을 게
5분동안 내가 로긘 안하면 날 차…! 내가 차일게..
multiful get 여러 파일 왕창


실습 실시간 로그
[root@centos7-10-1 docker]# tail -f /var/log/secure | cat -n

우분투에서 센토스로 뭔갈 하면

ssh 연결으로 처음엔 연결 성공
끊고 다시 연결 하는데 비번을 일부러 몇번 틀린 뒤 로긘 root 로긘 해서 다시
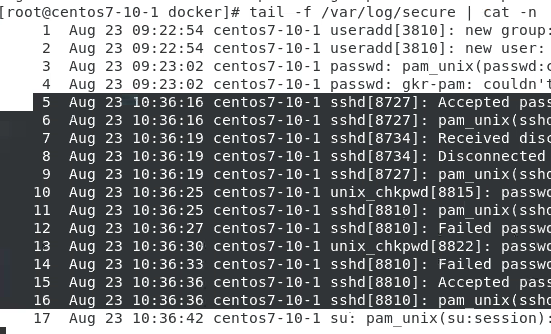
센토스에서 로그 확인하면 늘어나 있다!
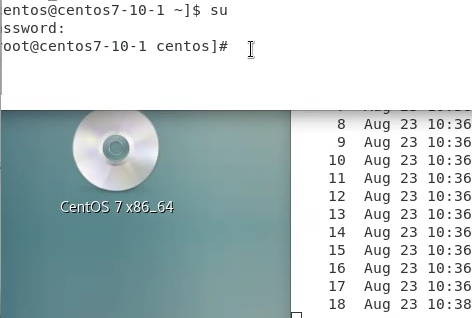
다른 터미널에서 로그인 해도 로그가 뜬다.
head/tail 과 tee 실습
실습
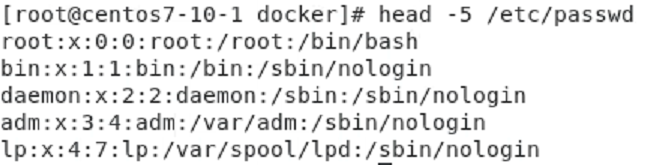
내용을 보면서 하고 싶다.

tee 는 화면에 보이면서 동시에 저장해라 .


내가 집어넣은 명령이 저장된다.
ls 하면

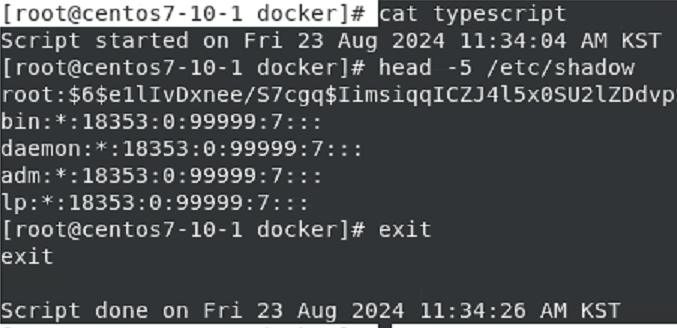
물론 nano typescript 해서 편집도 가능하다.
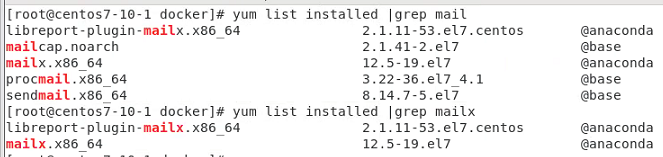
mail, mutt, mailx
콘솔에서 직접 메일을 보낼 수 있다.
이들을 실행하려면 사전에 시스템에 텍스트 화면에서 메일을 주고 받을 수 있는
MX(Mail Exchange) 서버 프로그램 sendmail 이 설치되고 실행되고 있어야 한다.
메일 실습
[root@centos7-10-1 docker]# yum -y install sendmail
[root@centos7-10-1 docker]# yum -y install mutt
-s 주제/제목

reach 는 멋진 단어.






history 팁!
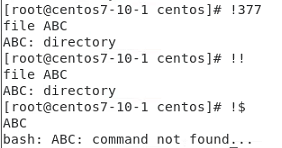
!! 명령어는 마지막으로 실행한 명령어를 반복해서 실행
!$ 명령어는 이전 명령어의 마지막 인수를 참조하는 단축키
cmp, comm, diff 파일 비교 명령어
cmp 는 두 개의 파일에서 차이가 있는 곳을 표시. compare(비교하다)
comm 은 공통적인 부분
diff 는 두 파일의 차이나는 곳을 정확히 보인다. <= patch 파일 생성 시 사용한다.
실습
실습 cmp


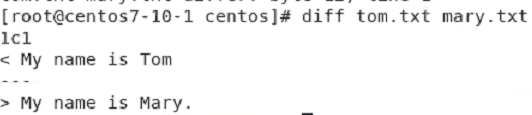

한줄로 되어 있어서..



공통적인 것을 맨 오른쪽에 보이고
첫번째 파일에서 유일한 것인 맨 왼쪽
두번째 파일에서 유일한 것이 중간

split 파일 분할
유용하게 쓰인다!!!
split A B 하면 A 를 분할한다.
옵션으론 -b (바이트 단위), -l (줄 단위) 분할이 있다.
실습 파일분할

22바이트씩 잘라서 저장을 하는데 PASS~, PASS~ 로 저장되어라.

졸라 많다..>!

옵션을 줘서 줄수로 자를 수도 있다.
sort
오름차순 혹은 내림차순 (-r) 으로 파일 내용을 정렬할 수 있다.
실습 sort

하면 abcd 순서대로 나온다.

sort -r 하면 반대로 나온다.
자주 쓰는 정규표현식
정규표현식 매우 중요!!
| { } | { }의 어느 문자와 매치되면 실행함 <={Aa} |
| \ | \뒤의 것이 특수문자인 것을 표시함 <= \( |
| | | | 앞의 실행결과를 | 뒤의 입력으로 함 |
| & | 백그라운드로 실행함 |
| !숫자 | history에서 해당 숫자의 명령어를 실행함 |
| * | 임의의 여러 문자 |
| ? | 임의의 한 문자 |
| [ ] | [ ] 범위에 매치되는 문자 <=[a-z] |
| > | > 앞의 실행결과를 > 뒤의 입력으로 함 |
| >! | > 앞의 실행결과를 > 뒤로 강제 입력함 |
| < | < 뒤의 실행결과를 < 앞의 입력으로 함 |
| >>, << | >> 앞의 실행결과를 >> 뒤로 추가함 |
| 2> /dev/null | 표준 에러를 콘솔에 표시 안 함 |
| 2>& 1 | 표준 에러를 표준 출력으로 보냄 |
| 2>& /dev/null | 표준 에러를 파일이나 장치로 보냄 |
| A>& B | A 파일의 출력을 B 파일의 입력으로 써줌 |
| A<& B | B 파일을 읽어서 A 파일의 출력으로 써줌 |
| 0> A | STDIN : 키보드 입력 |
| 1> A | STDOUT : 화면 출력 |
| 2> A | STDERR : 화면 에러 |
정규표현식 실습


{} 한번에 만들 수 있는 명령어

document, docdraft
fallreport winterreport sprintreport
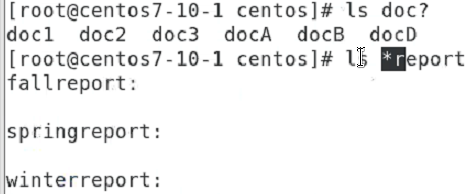
정규표현식을 사용하여 검색할 수 있는 명령어
-> grep, fgrep(grep -F), egrep(grep -E)와 pgrep
| [aeiou] | a, e, i, o, u 중 어느 문자라도 들어있는 것 |
| [a-z] | a부터 z 사이의 문자가 들어있는 것. 알파벳 소문자 |
| [a-z][A-Z] | a부터 z 사이와 A부터 Z 사이의 문자가 들어있는 것. 알파벳 대소문자 |
| [0-9] | 0부터 9 사이의 숫자가 들어있는 것 |
| ^[ ], [^ ] | ^[ ]는 [ ] 내용으로 시작됨, [^ ]는 [ ] 내용의 부정 <= ^[^#$] |
| ^pattern | 주어진 패턴으로 시작되는 줄 <= ^# |
| pattern$ | 주어진 패턴으로 끝나는 줄. 단독으로 $를 쓰면 빈 줄 <= #$ |
| ^[a-z][0-9]$ | 시작은 a부터 z 사이의 문자, 끝은 0부터 9사이의 숫자인 줄 |
| [.], [...] | .는 임의의 문자 1개, ...는 임의의 문자 3개 <= [a...z] cf. a???e |
| pattern+ | 이전 패턴과 하나 이상으로 매치되는 어구 <= root+ |
| pattern* | 이전 패턴과 매치되지 않는 어구 <= root* |
| pattern? | 이전 패턴과 하나만 매치되는 어구 <= root? |
| (abc)+ | 'abc' 패턴과 하나 이상으로 매치되는 줄. +는 적어도 하나 이상을 의미 ()는 여러 정규 표현식을 하나로 묶기도 한다 |
| v | 부정의 의미 <= v #는 #이 없는 줄을 보임 |
| c | 갯수를 표시 <= c #는 #이 있는 줄의 갯수 |
| | | 두 개의 정규 표현식에서 OR 의미 |
| {n}, {n,m} | 지정된 정규 표현식에 n번 일치, 최소 n에서 최대 m번 일치 |
| [: ~ :] | 클래스 [:alnum:] alnum은 영문이나 숫자와 일치 [:alpha:] alpha는 영문자와 일치 [:digit:] digit는 숫자와 일치 [:punt:] punt는 구두점(, . )과 일치 |
grep : filtering 역할
grep 의 옵션
| v / c | v는 일치되는 내용이 없는 줄, c는 일치되는 내용이 있는 줄 개수 표시 |
| n | 일치되는 내용을 줄 번호와 함께 표시 |
| i | 대소문자를 구별하지 않고 해당되는 내용이 있는 줄 표시 |
| e | 정규표현식 사용 |
| f | 찾으려는 문장이나 표현이 있는 파일지정 |
| l / w | l은 패턴이 포함된 줄(line), w는 패턴이 포함된 단어 표시(word) |
| r | 반복적으로 찾음 등이 있다. |
| => [a-e]는 {abcde}로써 a,b,c,d,e 중 하나, | |
| [ak] | a나 k 중 하나a나 k 중 하나a나 k 중 하나a나 k 중 하나 |
| ^a | a로 시작 |
| a$ | 로 끝남 |
| v # | #이 없는 줄 보임 |
| c # | #이 있는 줄의 갯수 |
| ls doc[A-E] | A, B, C, D, E 중 일치되는 것 모두 |
| ls doc[AE] | A나 E 중 일치되는 것 모두 |
| ls doc{A..E} | A로 시작 E로 끝나는 총 4자리 것 |
| ls doc{AE} | docA나 docE로 된 것 |
| =>^pass : pass 라는 단어로 시작되는 모든 줄 | |
| ^# | #으로 시작되는 줄 |
| ^$ | 모든 빈 줄 |
| #$ | #으로 끝나는 줄 |
| d...(...이 세 개) | d로 시작되는 총 네 자리 문자(d???) |
| [a-d]* | a에서 d까지 a,b,c,d 중 하나로 시작되는 문자열 |
| [Dd]atabase | D나 d로 시작되는 database라는 단어 |
| [^D] | D라는 문자로 시작되지 않는 줄 |
| c...d(...이 세 개) | c로 시작되고 d로 끝나는 총 5자리 문자(c???d) 등이 있다 |
정규표현식 패턴 검색 실습


줄의 개수를 보인다.
-v 는 부정 ~ 빼고

48 - 2 하면 46
주석이 있는 줄 보기

httpd 설정 파일에 주석이 많다!

#으로 시작하는거 빼고 grep 해라

첫줄이 #인건 다 빠짐. 얘네는 들여쓰기 되어 있어서 나온다.

#으로 시작되지 않는 애들 중에서 빈 줄도 빼고 보여라


=> 몇 칸 들여쓰기던 #으로 시작하는 애들이 아닌
=> . 이 한 칸이니까. 세 칸

이러면 첫번째 꺼가 안 빠져서

=> # 붙은 애들은 다 빠진다.
붙이면 기호를 못 알아 먹는다.
한 칸을 띄어야 # 앞에 몇개가 있던. ^ 그것으로 시작하는. 이렇게 해야 의미전달이 된다.

이렇게 하면 #으로 시작하는 애들 빈줄인 애들 다 없어진다.
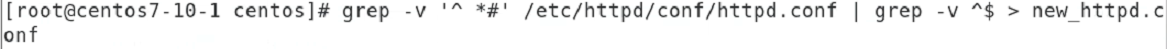
이렇게 하면 파일로 저장 된다.


r 이나 o 나 t 가 아닌거

rot 아닌걸로 시작되는 것.
r o t 로 시작되는 걸 빼고

r o t 아닌 것만
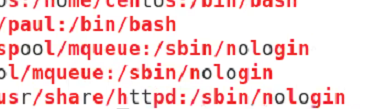

r 이나 o 나 t 로 시작되는 애

[^#$]는 # 또는 $로 시작하지 않는 줄을 의미
^는 부정(not)을 의미
#나 $가 아닌 문자를 찾는다는 의미

첫 번째
grep -v 명령어는 주석(#)으로 시작하는 라인과 공백 뒤에 #가 있는 라인을 제외합니다.
두 번째
grep 명령어는 이 출력 중에서 # 또는 $로 시작하지 않는 라인만을 필터링합니다.

egrep: 확장 정규 표현식을 사용하여 파일 내용을 검색하는 명령어입니다.
-v: 반전(inverse) 옵션으로, 주어진 정규 표현식과 일치하지 않는 줄만 출력합니다.
'^[[:space:]](#.)?$': 정규 표현식의 의미는 다음과 같습니다.
^: 문자열의 시작을 의미합니다.
[[:space:]]*: 공백 문자(스페이스, 탭 등)가 0개 이상 반복되는 것을 의미합니다.
(#.*)? : '#' 문자로 시작하는 주석이 있거나 없는 경우를 의미합니다.
$: 문자열의 끝을 의미합니다.
전체적으로 이 정규 표현식은 "공백으로만 이루어진 줄" 또는 " '#' 문자로 시작하는 주석 줄"을 나타냅니다.
변경 시켜주는 명령어 tr
tr 옵션 set1 set2’ 해서 set1을 set2로 변경해주는 tr에
[: :] 클래스를 사용하면 더욱 편리하게 작업할 수 있다.
tr 실습

위 아래 같다


의도한대로 안되기도 한다.

소문자를 대문자로 바꿔라
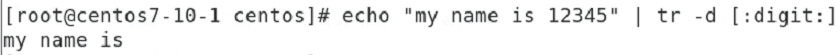
-d 빼라 숫자를

빼라 문자를

다빼서 암것두 안나온다.
큰 파일 만질때 굉장히 유용한 명령어들이다.
주석 지우기, 문자 지우기, 숫자 지우기, 문자 숫자 지우기, 소문자 대문자로 바꾸기, 대문자 소문자로 바꾸기.




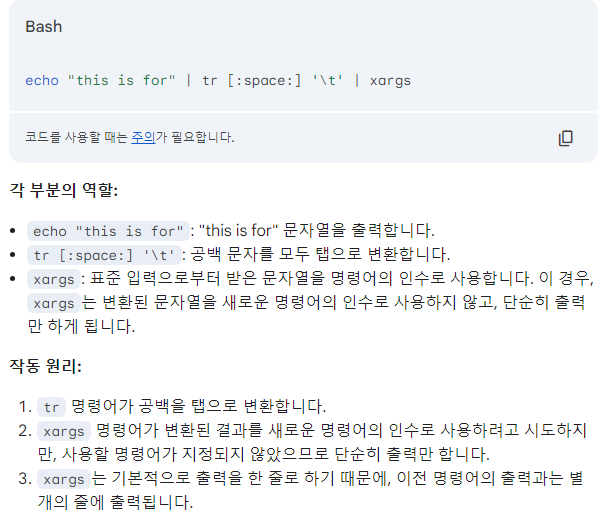
echo "this is for testing" | tr [:space:] '\t' | xargs
cut : 쓸모가 많고 필요한 부분을 추출하는 명령어
==> BigData 분석에서 여러 항복들이 있는데 그 중에서 분석에 필요한 항목들만 추출한다면 이 기법이 좋다. <=Data PreProcessing(데이터 전처리) 과정의 일부이다.
-d : delimiter, separator 로 Tab, Space, , , :, #, ; 등
-f : 어느 열(column)을 보일지 지정
cut -d “:” -f1,7 /etc/passwd 식으로 한다.
실습

빅데이터 분석에서 많이 쓴다. 빅데이터에서 데이터 갈무리를 할 때 많이 사용한다.
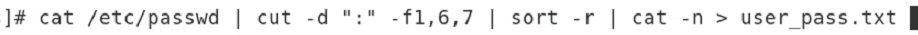
: 를 기준으로 나눠서 첫번째 6번째 7번째 항목만 뽑아서 ~~

awk
cut 과 유사하나 -F 로 필드(column) 지정, -f 로 파일 지정 사용가능.
awk -F “:” ‘{print $1,$7}’ /etc/passwd
이 도구는 다른 프로그래밍 도구와 연계가 잘 된다.
실습

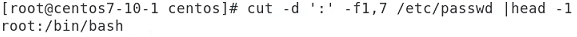
**************** 중요
sed 파일을 편집해서 보이는 명령어
'sed [option] 명령어 파일_명'
여러 옵션과 복잡한 구문을 가지고 있지만 잘 사용하면 정말 강력한 편집기
실습


2번째 줄만 보인다.
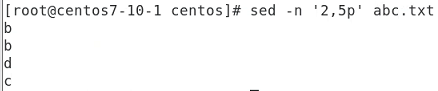
p 는 줄?이래 맞나 이따 정리할때 확인
원본을 바꾸지 않겠다. sed -e
원본을 읽겠다. see -n
원본을 바꾸지 안고 보겠다. 첫번째 줄 다음에 e 를 넣겠다.

$ 맨 뒤에 z 추가(a)

i == insert
a == add
첫번째 줄에 f를 추가

줄마다 공백을 줄 땐 대문자 G를 준다.
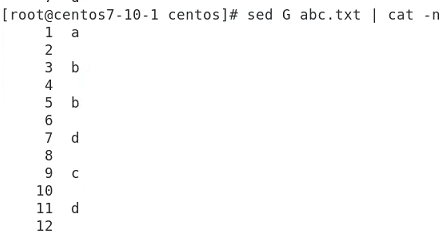
서브스튵ㅌㅌ?
/g == 각 줄 마다
오후 3시 32분

b는 다 M으로 바뀜

c -> N

네번째 줄 삭제

2번째줄 5번째 줄 빈칸으로 만들어버렷
여러개가 있으면 g

특정 어구를 찾을 땐
2~5 줄을 p 보여라

b 로 시작되는 줄을 보여라

b 또는 c 로 시작되는 애를 보여라

b 또는 c 로 시작되는 애들 빼고

첫번째 줄 다음에 AAA를 추가해라 저장해라

원본은 바꾸지 않고 대체하겠다. root를 ADMIN 으로 그리고 ADMIN 부분을 뽑아보여라

1~5 째 줄에서만 대체하겠다. root 를 ROOT로 바꿔라 여러줄에서 | ROOT 뽑아보여라

3번째 줄부터 끝에줄까지 d 지워라

두줄만 보인다.
# 주석으로 시작하는 줄번호 지워잉

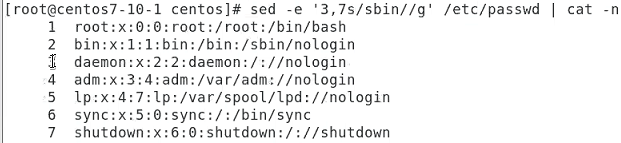
3번째 줄부터 7번째 줄까지(/etc/passwd 파일의 3번째 줄부터 7번째 줄까지)에서 (/s/) /sbin/ 문자열을 (/sbin/) 공백으로 치환한다(/g)는 의미입니다. 즉, /sbin/ 부분을 지워버리는 것이죠.

공백줄만 삭제해라
sed '/^$/d' 파일명
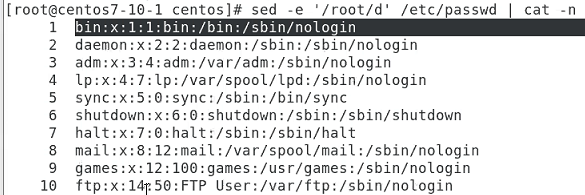
"root" 문자열이 포함된 줄을 삭제(delete)하라는 의미입니다. 즉, "root" 사용자에 대한 정보를 가진 줄을 제거합니다.

주석과 빈줄을 모두 빼는거
sed '/^#/d; /^$/d' 파일명
<실습>
cp -arp /root/initial-setup-ks.cfg text.lst 해서 실습할 파일을 복사해두고
sed -n '3p' text.lst =>3 번째 줄 보기
sed -e 's/System/SYSTEM/' text.lst =>모든 System을 SYSTEM으로 변환
sed -e '14,20s/System/SYST/' text.lst =>3~9줄에서 System을 SYST로 변환
# sed -e '14,20s/System/SYST/' text.lst | cat -n | grep "SYST"
14 # SYST services
18 # SYST language
sed -e 'a\INST\!' text.lst =>각 줄 아래에 INST! 추가
sed -e 'a\' text.lst =>각 줄 아래에 빈 줄 추가
sed -e '3a\INST' text.lst =>3줄 다음 줄에 INST 추가(4번 줄에 보임)
sed -e 's/^/(tab)/' text.lst =>첫 줄을 (tab)만큼 띄워서 씀
sed -e '3,9s/^/#/g' text.lst => 3~9줄 모두 주석# 추가
sed -e "4s/#//" text.lst => 4줄에서 주석# 제거
sed -e '/^$/d' text.lst =>모든 공백 제거
sed -e '/System/d' text.lst =>모든 System 제거
sed -e '14,20s/System//g' text.lst =>3~5줄에서 System 제거
sed -e '1,$s/System//g' text.lst =>처음부터 마지막 줄까지에서 Sytem 제거
sed -e '3d' text.lst =>3줄 제거
실습
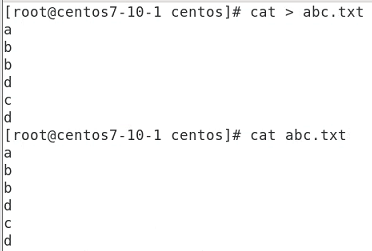

2번째 줄만 보인다.
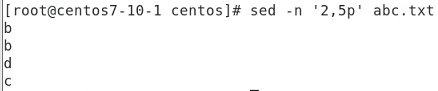
p 는 줄?이래 맞나 이따 정리할때 확인
원본을 바꾸지 않겠다. sed -e
원본을 읽겠다. see -n
원본을 바꾸지 안고 보겠다. 첫번째 줄 다음에 e 를 넣겠다.

$ 맨 뒤에 z 추가(a)
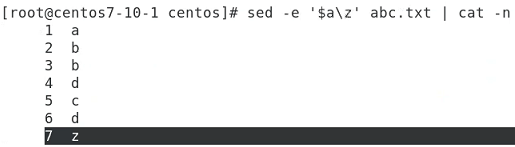
i == insert
a == add
첫번째 줄에 f를 추가

줄마다 공백을 줄 땐 대문자 G를 준다.
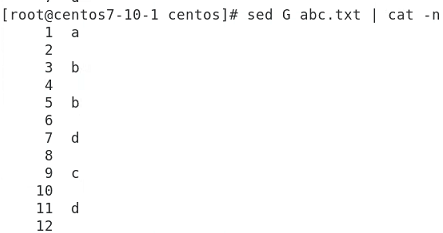
서브스튵ㅌㅌ?
/g == 각 줄 마다
오후 3시 32분

b는 다 M으로 바뀜

c -> N
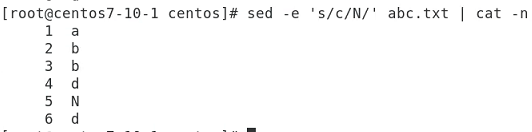
네번째 줄 삭제

2번째줄 5번째 줄 빈칸으로 만들어버렷
여러개가 있으면 g

특정 어구를 찾을 땐
2~5 줄을 p 보여라

b 로 시작되는 줄을 보여라

b 또는 c 로 시작되는 애를 보여라

b 또는 c 로 시작되는 애들 빼고

첫번째 줄 다음에 AAA를 추가해라 저장해라

원본은 바꾸지 않고 대체하겠다. root를 ADMIN 으로 그리고 ADMIN 부분을 뽑아보여라

1~5 째 줄에서만 대체하겠다. root 를 ROOT로 바꿔라 여러줄에서 | ROOT 뽑아보여라

3번째 줄부터 끝에줄까지 d 지워라

두줄만 보인다.
# 주석으로 시작하는 줄번호 지워잉

3번째 줄부터 7번째 줄까지(/etc/passwd 파일의 3번째 줄부터 7번째 줄까지)에서 (/s/) /sbin/ 문자열을 (/sbin/) 공백으로 치환한다(/g)는 의미입니다. 즉, /sbin/ 부분을 지워버리는 것이죠.
공백줄만 삭제해라
sed '/^$/d' 파일명
"root" 문자열이 포함된 줄을 삭제(delete)하라는 의미입니다. 즉, "root" 사용자에 대한 정보를 가진 줄을 제거합니다.
주석과 빈줄을 모두 빼는거
sed '/^#/d; /^$/d' 파일명
(개인 필기에 추가 실습 문제들 있음!)
여기까지